Situation
Migrating your applications from Legacy DC to AWS might sound very easy as a first impression. From a business perspective, this is usually as simple as “lift and shift”, but only a “DevOps Engineer” knows the challenges that are associated with it and for a budding Solution Architect, this is the perfect opportunity to show what they are truly capable of.
That being said, let’s go through the following pointers to understand the situation we were in –
- Payments / PG Services are deprecating DC and we need to Migrate to AWS.
- Whilst being a migration, this is also an opportunity for us to leave legacy management systems behind and adapt new AWS technologies to make the system easily scalable,de-coupled while keeping the costs low.
- A solution that can integrate with AutoScaling, ALB, S3, etc needs to be built to use most of the AWS services.
Tasks and Objective
One of the best ways to create a solution is to divide the problem into smaller parts, identify the tasks, and finalize the objective.
After gathering the complete requirement from the applications owners and a lot of brainstorming sessions, we jotted down below points to create the solution –
- AWS CodeDeploy was chosen as the deployment service around which the whole solution was built.
- We needed to achieve that deployments should be synced on new instances in Autoscaling Group
- Backing up application logs to s3 regularly and at the time of termination
- Making the application stateless(almost) and a single deployable unit
- Auto-discovery in monitoring agents
- Control over rolling out new builds in a canary way
- Using a combination of spot and “on-demand” ec2 instances to save costs
- Making this a type of solution which can be standardized and used across multiple services.
Action
Before going into the actual setup, let us go through what Codedeploy is and its advantages.
What is AWS CodeDeploy?
CodeDeploy is a deployment service that automates application deployments to Amazon EC2 instances, on-premises instances, serverless Lambda functions, or Amazon ECS services.
Advantages of AWS CodeDeploy
- Can directly communicate and seamlessly integrate with AWS Services such as ASG, S3, etc
- The service scales with your infrastructure so you can easily deploy to one instance or thousands.
- CodeDeploy can deploy application content that runs on a server and is stored in Amazon S3 buckets, GitHub repositories, or Bitbucket repositories.
- We can stop and roll back deployments at any time.
- We can define health checks in custom made scripts to validate if the service is up
- It ensures that all the servers in the autoscaling group are deployed with the current revision as soon as they start up.
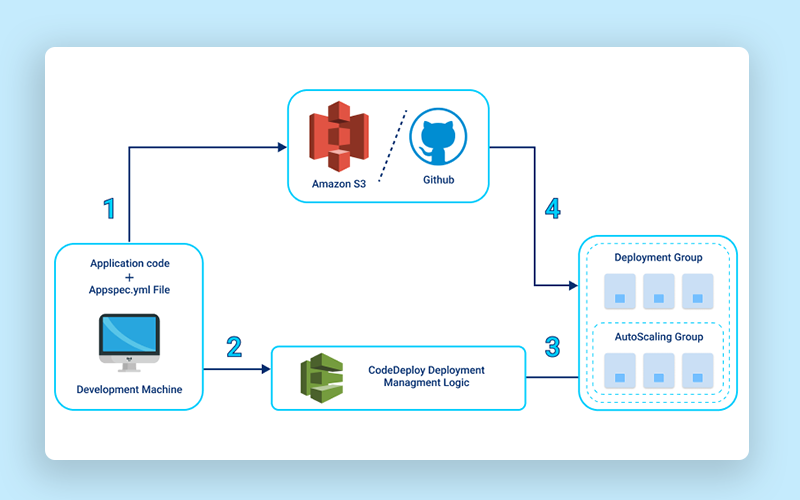
CodeDeploy Flow
This diagram gives a basic understanding of how Codedeploy works.
We can use any source code repository with our source, the repository should contain an appspec.yml file that has the necessary hooks/steps which help in planning application start/stop and other custom scripts that you may wanna run during any deployment.
Refer – AppSpec File example – AWS CodeDeploy
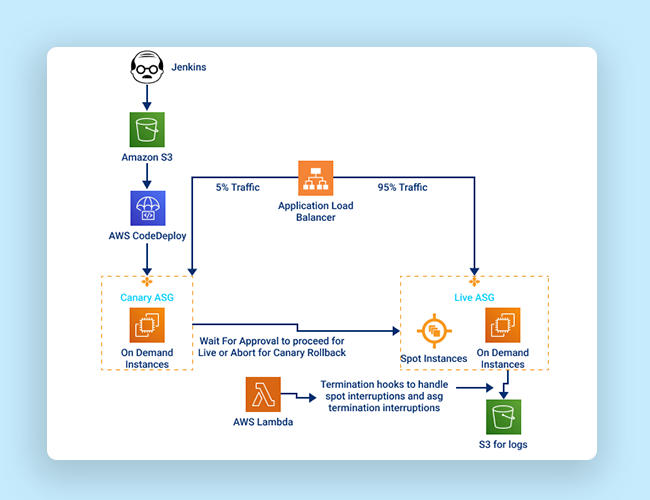
The Solution
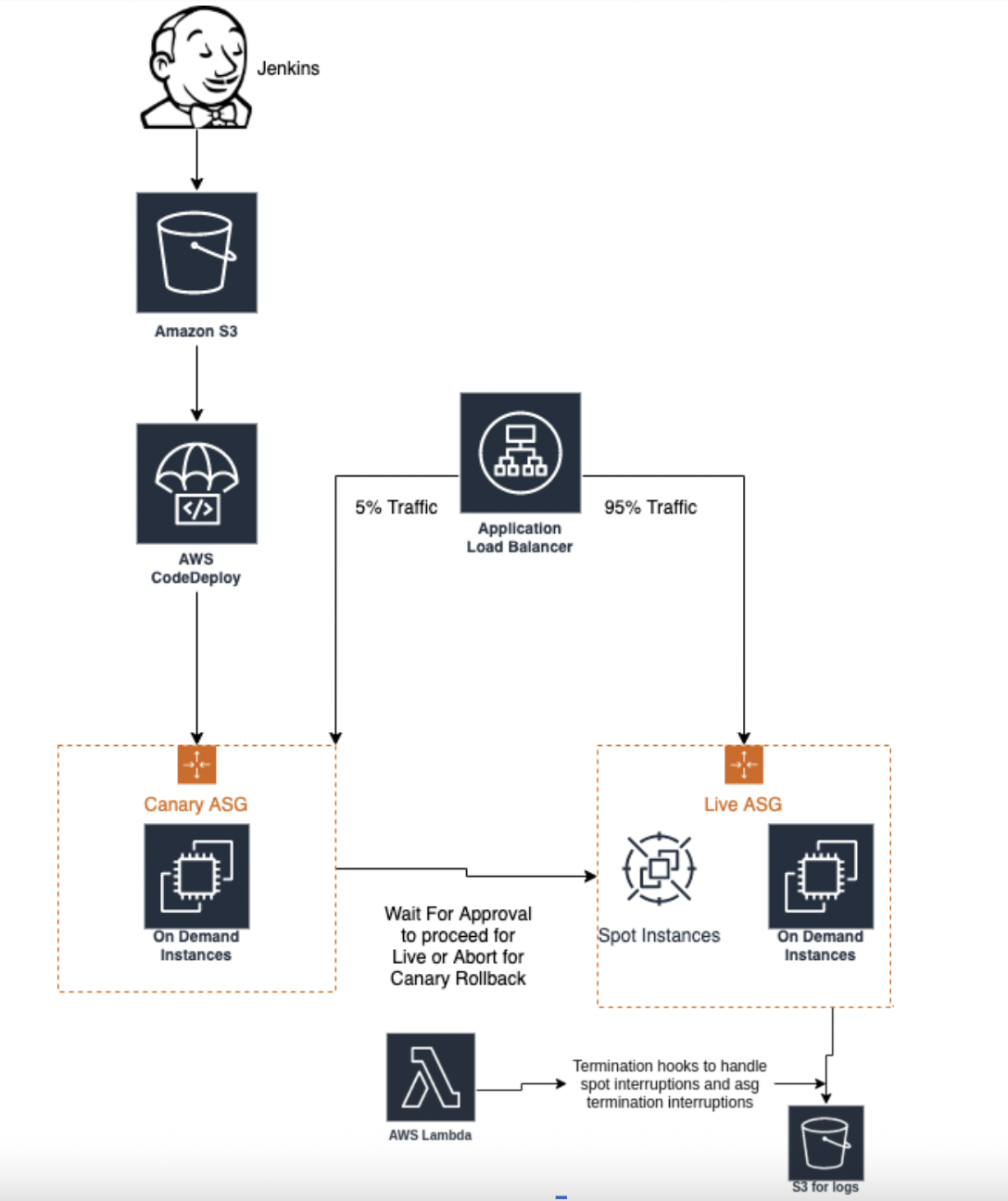
Explanation
- We have used Jenkins for build creation and a separate job to trigger deployment using the Codedeploy plugin on Jenkins.
- Codeploy plugin helps in creating the .zip file with our build(jar file), appspec.yml, along with other supporting scripts such as application stop/start, etc.
- At the Codedeploy console in AWS, we create an “application” and two deployment groups that will be used for canary and live instances.
- Each deployment group in Codedeploy is associated with a LoadBalancer/TargetGroup and Autoscaling group.
- Traffic distribution on canary vs live Target groups is managed at the ALB level.
- The overall flow of events is as below:
- Your build revision is uploaded in s3.
- New instances are launched for the canary.
- Steps are performed as per what we define in appspec.yaml on canary instances
- Health-check is verified for canary
- New Canary instances are made active in LB
- Older Canary instances are deregistered and then terminated
- At this stage we can wait and Monitor the Canary Servers, We get an option to approve the Canary and proceed for Live Rollout(Steps 2-6 are performed again for Live Instances) or Abort for Canary Rollback.
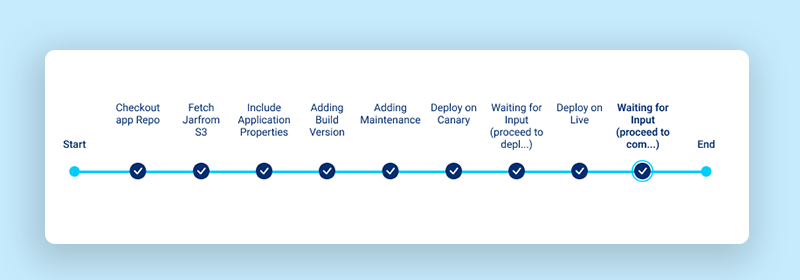
- Termination hooks are custom-made scripts that are running as a systemd process, this process makes the use of AWS metadata API to check for interruption notices on AWS spot instances and stop the application gracefully on these instances without affecting the current traffic.
Use of spot ec2 instances
When we go by the tagline by which AWS is portraying spot instances – “Run fault-tolerant workloads for up to 90% off”, this doesn’t seem like something you’d like to use for your production workloads, but this didn’t sit quite right with us.
We used our in-house cloud Opmitimizer tool – ” Paytm Optimizer ” to solve most of the problems that can come into our way while implementing Spot EC2 instances
Additionally, below initiatives to make sure spot interruptions are the least of our worries –
- Made application servers as stateless as possible.
- Ensured development best practices are followed and made sure any hardcoded IPs are not used anywhere in the code or properties.
- The Application/jar and application logs were the only stateful things on the application server.
- As we were using Codedeploy any new server will automatically be deployed with the same build and then any traffic was allowed in it.
- For log management, logs were being rotated and we were syncing logs to s3 every 1 hour, at the time of termination, we used ec2 metadata API to poll for spot interruption and take final logs backup before terminating the instance.
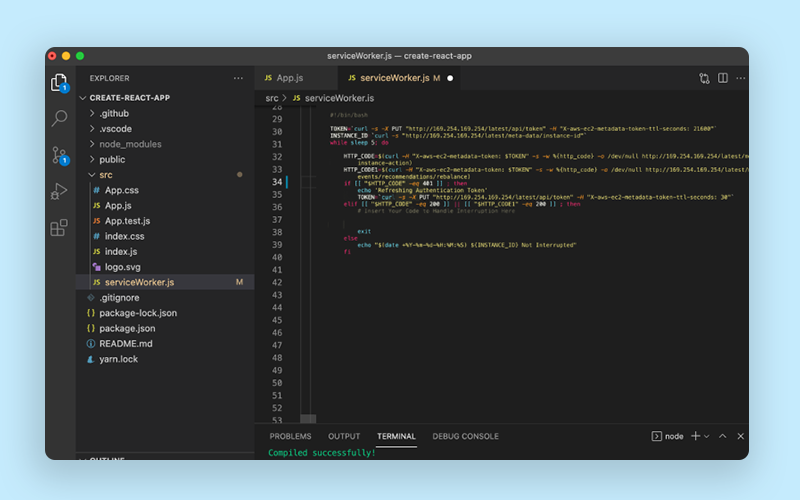
Clever use of ec2 userdata
Userdata is something that executes just after the server has started.
EC2 userdata was used to trigger ansible-pull for creating all the users on the server, installing/configuring a few security agents, monitoring agents, and setting up a few cron.
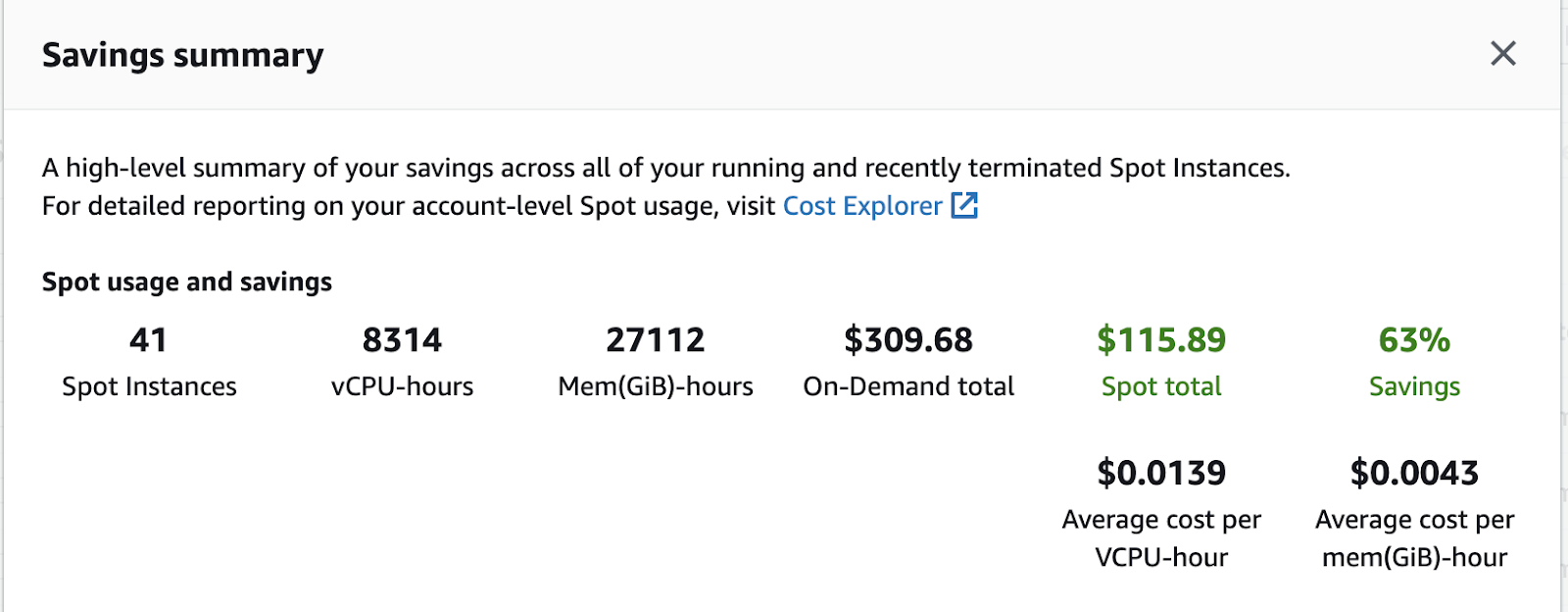
Result
The result was a robust solution that helped reduce the time spent on operations and the overall cost of the infra.
What we achieved –
- Autoscaling with 50% on-demand and 50% spot instances
- Zero Downtime and completely Managed Deployments
- Option For canary Deployment with 5% traffic
- Easily configurable options for blue-green, in place, and other custom deployment options.
- A solution that is now becoming standard and is used in managing around ~50 applications as of now
- Tremendous cost savings

Userdata is something that executes just after the server has started.
EC2 userdata was used to trigger ansible-pull for creating all the users on the server, installing/configuring a few security agents, monitoring agents, and setting up a few cron.
Result
The result was a robust solution that helped reduce the time spent on operations and the overall cost of the infra.
What we achieved –
- Autoscaling with 50% on-demand and 50% spot instances
- Zero Downtime and completely Managed Deployments
- Option For canary Deployment with 5% traffic
- Easily configurable options for blue-green, in place, and other custom deployment options.
- A solution that is now becoming standard and is used in managing around ~50 applications as of now
- Tremendous cost savings