
Paytm has been a pioneer in the industry when it comes to payments, the cutting edge technology and niche product which it delivers sets it apart from the competition.
One such innovation is Soundbox™ which has been widely received in the Indian market and also been showcased at various events. It has brought transaction trust and a sense of relief for the millions of merchants and people who use it, which in turn has reciprocated as a trust in the company.
Through the course of time Paytm has launched various offline devices complimenting Soundbox™. One such device is Soundbox™ 2.0 which has been launched in March 2021.
It has various additional features apart from the transaction play, which are mentioned below-
- Real time transaction summary play
- Battery drainage notification play
- LCD Screen at merchant end to display the Amount for additional security
With all these features this device indeed complements and enhances the current Soundbox™ 1.0 Capabilities but there was one important achievement which at first was a bottleneck but later gave inception to a neat software solution mentioned in the next sections.
Problem Statement
Soundbox™ 2.0 comes with a very little memory footprint(8MB). This memory is utilized for the following purpose-
- Application Storage- Business application developed by Paytm for the purpose of transaction facilitation. This takes on an average size of 350KB
- SDK Storage- SDK is shared by the vendor which has the low level driver specific functionality which is utilized by the application storage. This takes on an average size of 500KB
- Resource Storage- It contains all the static sound files in *.wav format which is to be played whenever a transaction happens or for any auxiliary tasks like battery notifications, volume controls etc. When combined in a single bundle the total space acquired by the sound files comes out to be 2.8MB
- Secure Flash segment- The memory area which used to keep private keys and certificates. The total space acquired by it is 50KB
- 4MB is reserved as program memory for application binary and SDK binary which cannot be changed (Restriction imposed by OEM). Only 4MB is provided as a file area which will be used to store additional resources ( sound files ) if new ones are added/updated in future. This space is also used to temporarily store over the air updates for application / SDK till the time it’s moved to program memory on reboot
After calculating the total storage space acquired by resource files and secure memory segment we were left with little over 1MB, which will be used for-
- Temporarily storing the FOTA ( firmware over the air updates) for Application and SDK
- Resource Updates – If any new sound file is added / updated
Bottleneck
As mentioned the total space available for storage was little over 1MB and will be used for App/SDK updates and resource updates. This raised a lot of issues which are mentioned below-
- This device should support multiple languages and that would require entire bundle of sound files to be pushed in a single attempt, which did not seem possible as the free space was only 1MB but the sound bundle size was close to 2.8MB
- Devices may experience intermittent connection losses which could result in frequent download failure and downloading the entire package all over again would result in bandwidth loss
- We use 2G enabled devices which have very limited bandwidth so downloading data in a few hundred KBs / MBs could be a challenge
- There was no support provided by the vendor for packing all the sound files using a packaging tool and standard packing mechanisms like zip or gzip are not supported in these devices as they work on RTOS
All of these issues needed to be addressed in order to create an efficient mechanism to push the updates on the Soundbox™ 2.0 devices.
Planning & Resolution
Over the air updates for application and resource download were a major blocker and needed swift task planning and innovative strategy to be executed. So we prioritized the challenges and looked for an approach that could solve all these problems one by one –
- The OEM does not provide us the zip package to bundle the sound files into a single package which was causing us to generate x number of updates for x files, which is impossible to manage as there can be x number of files and triggering the update invocation process for a single device will create x number of jobs at AWS ioT and will subsequently result in storage control for all these files in S3, so we needed a mechanism which could package the files into a single package.
- Once clear with the task for this particular problem, We decided to create / use an existing open source solution that can be ported after some code changes for our embedded device.
- Devices running in the Indian market work on 2g connectivity which causes a lot of connectivity issues so we need to devise a way which could enable the approach of pause and resume of downloads once the connectivity is good rather than starting the download process all over again.
- Maintaining the integrity of data is important once we are downloading so we need to use SHA256 checksum approach for the downloaded chunks.
- An Efficient approach to download and update the downloaded files so that no extra space is used and we can download the entire bundle of resources ( sound files ) in smaller chunks that fits the available memory space and can facilitate the entire resource file download of 2.8MB.
Action
Once clear with the requirements to be met in order to develop a successful process for over the air updates, we started working towards that.
- Packaging tool Identification – This was the most important piece of the puzzle, We did a lot of research at our end to identify how files should be packaged and how does existing packaging systems work and after that thought of using huffman variable length encoding [link] to encode the files in a single package which will not only package the files in a single package but also compress the overall package size by 20 to 30% which is critical for data usage in devices. We found an online solution for huffman variable length encoding system [link] in the language of our choice( C ) which was already compressing all the files into a single bundle. After that the decompression logic was built using the open source decompression library and development changes for porting the decompression logic was done.
- Multi part/Range driven Downloads – Although now it was possible to bundle the sound files into a single package and the decompression can be done on device but there was no way to download large files as there was only 1MB space in the device and although we were using efficient compression techniques too but the size after compression also was pretty big ( 2.2 MB ) and this need to decompress too which in turn will require additional storage of original file size ( 2.8 MB ) so there was a strong need to devise an approach which could break down this compressed file bundle into smaller chunks. This gave inception to an innovative software solution-
- Modify the compression library – A range based filter was added in the compressed file. Initial 5 bytes were reserved according to the chunk size specified by the user and the same changes were done at the device end to download the data using range selection by specifying range parameter in the http download request, for example-
- HTTP/ s3.ap-south-1 GET <presigned url>
- “Range: bytes=x-xxxxx”
- Modify the compression library – A range based filter was added in the compressed file. Initial 5 bytes were reserved according to the chunk size specified by the user and the same changes were done at the device end to download the data using range selection by specifying range parameter in the http download request, for example-
Once one chunk is downloaded it contains the entire compressed data for the compressed files in that chunk and additional 8bytes for the next chunk range.
- Decompression Logic optimization – After a chunk download happens it is immediately decompressed and sound files are updated so that the acquired storage space is not essentially utilized. By doing this, we are only saving the chunk size temporarily ( recommended 300KB ) and freeing it after sound file updates so that entire storage space is available for the next chunk.
For example-
Input Compressed Data :
| Range bytes | Compressed data | Range bytes |
Device Download Process-
* Read range byte if a new download is initiated
| Range bytes |
*Once Range bytes are read the compressed data and subsequent chunks
| Compressed data | Range bytes |
- Data Integrity Check – The integrity of data download needs to be verified in order to prevent any data corruption issues in the devices so once the compressed chunk is downloaded integrity checks should be done and after that the decompression will be done. This required additional set of changes mentioned below –
- Added the SHA 256 checksum for every chunk compressed using compression library – SHA256 checksum is an industry standard way to ensure data integrity [link]. The existing compression library source code was modified in order to append the sha256 hash for the compressed file data along with additional range based bytes. An open source contribution [link] project was modified and integrated with the compression library to achieve this.
The same changes were done at the device end to do data integrity checks for chunk downloads and data integrity. Now after the compressed data an additional 64 bytes SHA256 hash was added to verify the integrity of compressed data.
Input Data
| Range bytes | Compressed data | SHA256 Hash | Range bytes for next chunk |
Once the entire compressed data is downloaded as per the range size
Additional hash information and range for the next chunk is downloaded till the time device encounters an end of download pattern specified during compression.
Download and Decompression at device end – If the device does not know the range bytes ( it can happen if the device download has initiated ) in that case the device will download range bytes first and then start downloading compressed data.
| Range bytes | Compressed Data |
After compressed data is downloaded as per range, the device download additional 72 bytes ( 64 bytes of SHA256 + 8 byte for next packet )
| SHA 256 Hash | Range bytes for next chunk |
It then does data integrity checks for the device and if successful request the next packet using the range bytes for the next chunk.
- Intermittent Connectivity Issues – During large downloads of few hundred KBs of subsequent chunk it may be possible that the device will suffer from connectivity issues which could potential trigger the download of same update all over again resulting in data loss and could potentially result in infinite loop where the device will keep on downloading the updates without being successful.Handling this was critical for the overall solution to work so some updates were made on top of the above work done to ensure that an offline storage of meta information is done, Steps taken for this task is mentioned below-
- Device stores the job id information when it is triggered from AWS and is received by device
- Device stores the range bytes for the particular job ID
- Each compressed file bundle contains the routing table of huffman encoding technique which is downloaded at the start of download. This information needs to be saved as well because even if the device has a range parameter which tells where to download the data from which once downloaded has to be decompressed according to the routing table information
After saving all the information given above device can check if its the same job id which was downloaded partially and it has range information and has the routing table for the same then it picks the range from the range cache and start reading from the specified range rather than from the start, This resulted in optimization of downloading process which could potentially work in pause and resume download process in devices.
With the changes done above, we have significantly enhanced the AWS update process and were successfully able to download the files of large sizes.
High Level Design
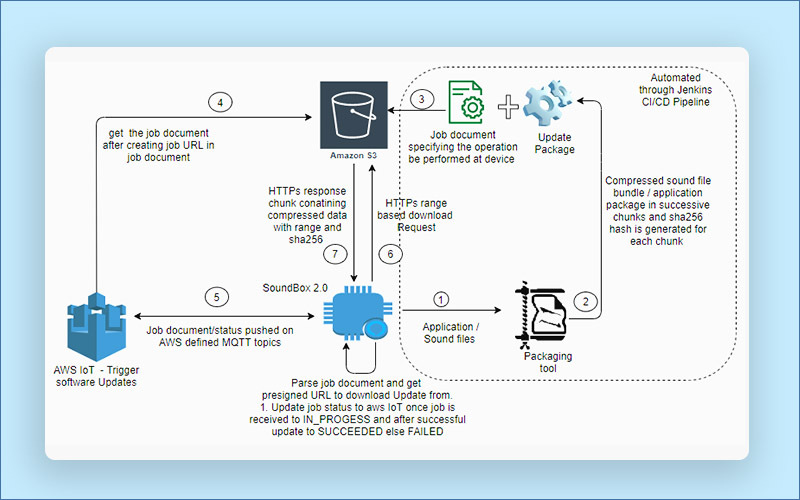
Result
With the changes mentioned above, the over the air updates process was entirely transformed to scale for large files and these are some of the major milestones we accomplished during the course of it.
- A Packaging tool is built which can compress and package files – This is owned by PayTM now and dependency from OEM is reduced
- Data integrity logic was integrated in the packaging tool
- Able to successfully leverage open source contribution to create a new process to package, compress and enable checksum based data integrity
- A range based HTTPs solution has been created on top of compressed data which is completely new in the embedded space
- Download strategy is created to ensure that the network connectivity issues can be handled without the need to download the entire update bundle again
- Language migration from English to Hindi or any other language is not an issue now as storage space is optimized now to update the existing sound files easily
