
We are India’s leading financial services company that offers full-stack payments and financial solutions to consumers, offline merchants, and online platforms. Being a tech innovator, our endeavour is to always enable technology-first solutions for our consumers and merchants.
For this, we planned to migrate a large amount of Simple Storage Service (S3) data, an object storage offering, from one AWS region (Mumbai) to another (Hyderabad), which AWS launched recently. This prompted us to act quickly and create a comprehensive migration plan that took into account the duration, cost, data integrity, and seamless integration with our application. Our strategy had to address critical questions such as:
- How long will the migration take?
- What will be the overall cost?
- How will we maintain data integrity during the process?
- How will our application seamlessly transition to accessing the newly migrated data while still serving older data from the previous region?
Why Migrate S3 Data to another region?
The goal is to ensure that static content is always available, and to use CDN failover for object-level redundancy, all while minimizing any impact on business operations and guaranteeing the integrity and accessibility of data. Some of the most common reasons include.
Disaster Recovery (DR): To ensure that critical data and systems can be recovered in the event of a disaster or outage. The goal of disaster recovery is to reduce downtime and data loss in the event of an unanticipated interruption, such as a natural disaster, cyber-attack, or hardware failure.
Cost optimization: Data storage costs vary significantly across regions, and users can reduce their overall storage costs by migrating to a more cost-effective region.
Performance optimization: Data access speeds can also vary between regions, and by migrating to a region with faster access speeds, users can improve their overall data access performance.
Streamlining frequently accessed data: In s3 performance for files, access is dependent on how data has been organized in prefixes as you need in parallel to achieve the required throughput. So the idea was to identify prefixes that were heavily accessed and clean up files that were never accessed
There are several methods available for migrating S3 data from one region to another, including the following:
- S3 Transfer Acceleration: This feature allows users to speed up their data transfer by using Amazon CloudFront’s globally distributed edge locations.
- S3 Cross-Region Replication: This feature allows users to automatically replicate their S3 data to another region in real time.
- S3 Data Export: This method involves exporting the data from one region and importing it into another.
- S3 Batch Operations: Amazon S3 Batch Operations can play a key role in cross-region data migration by enabling you to perform large-scale batch operations on Amazon S3 objects. With S3 Batch Operations, you can perform operations such as copying, tagging, and deleting objects in your S3 buckets at scale, without having to write custom code.
There were many buckets for migration, but one bucket had a storage capacity of about 450TB and held about 5 billion objects, mostly static content like images, JavaScript files, CSS, and HTML files. These files were mostly served by a CDN for legacy applications built over a decade ago. Unfortunately, no S3 object cleanup policy has been implemented. After careful examination, we discovered that approximately 1.5 billion objects were either marked for deletion or were outdated (non-current) versions. We decided to clean up such objects in order to streamline the migration process and reduce costs.
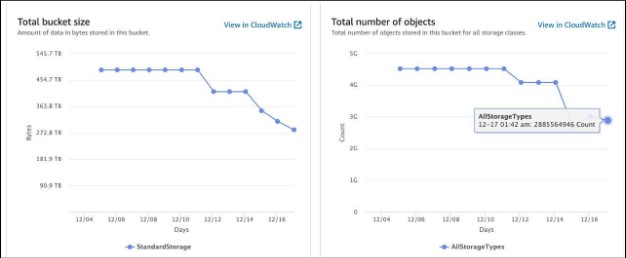
The next step was to determine the best method for migrating our data. After careful consideration, we decided to utilize both S3 Cross-Region Replication and S3 Batch Operations, as they offered the ability to replicate both data and metadata, ensuring data integrity and reliability. However, we determined that S3 Transfer Acceleration, while a viable option, was too cost-prohibitive for our large-scale Petabyte data transfer. To ensure a low-cost solution that met our goals and expectations, we consulted with our AWS solution architect to gather their expert insights.
To proceed with our migration plan, we enabled S3 Cross-Region Replication to replicate newly created objects and created an S3 Batch job to generate manifest files for one of our larger buckets, which held billions of objects and terabytes of data. Despite the job status indicating that it was still in progress, it took several hours to complete the manifest generation process. Upon consultation with the AWS support team, we decided to cancel the job since the manifest had already been generated. To mitigate potential rate limiting and network bandwidth issues, we divided the manifest into smaller batches for a more efficient migration.
Finally created multiple S3 batches and initiated data transfer from one region to another.
Problem:-1. How to perform S3 objects level failover.!!
One of the main challenges we faced was ensuring a smooth transition for our application to access the newly migrated S3 data while still serving the older data from the previous region. To tackle this, we had a consultation with our CDN provider and sought a customized solution that would allow content to be accessed from the primary location, and in the event of content unavailability, a failover to the secondary location would occur based on certain HTTP response codes. The following diagram provides a high-level overview of the architecture.
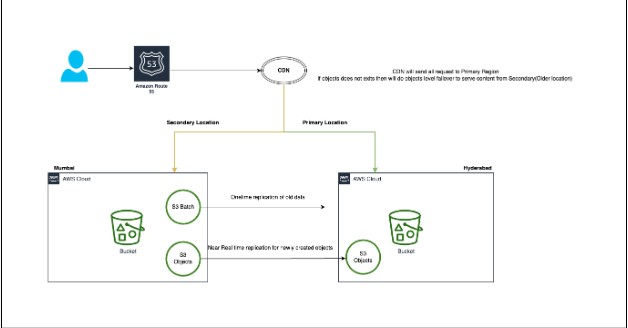
Finally, we conducted thorough testing to confirm that everything was functioning as expected.
Note:- Failover occurred at the level of individual objects (files), rather than at the S3 bucket level. While achieving bucket-level failover is relatively straightforward, the same cannot be said for objects-level failover
Wait… our celebration was not even over and we encounter one more challenging problem.
Problem:-2. The hardcoding of S3 object URLs in some of the legacy applications resulted in direct hits to the S3 bucket, bypassing the CDN endpoint. This raised several concerns, including the identification of the number of objects being accessed directly, the applications making these direct calls, and the best approach to address this issue.
To resolve the issue of direct hits to the S3 bucket, bypassing the CDN endpoint, we evaluated various solutions, but none met our expectations. As a result, we chose to develop custom code in Python that would analyze the S3 access logs based on the host header and generate daily reports of unique objects, along with their access count, that was being directly accessed by the applications. This allowed us to identify and remove the hardcoded URLs and redirect the calls to the CDN endpoint for optimal performance.
Problem:-3 Failure of millions of objects during S3 batch processing due to inappropriate permission.
S3 Batch Operations is a powerful tool for managing large amounts of data in Amazon S3, but it does have some disadvantages that you should be aware of:
Complexity: S3 Batch Operations can be complex to set up and manage, especially for large-scale operations. It requires a deep understanding of AWS S3 and the batch operations process.
Limited Operations: S3 Batch Operations only supports a limited set of operations, such as copying, tagging, and deleting objects. If you need to perform more complex operations, such as transforming data or aggregating data, you will need to use other AWS services in conjunction with S3 Batch Operations.
Performance: S3 Batch Operations can be slower than other methods of data migration, especially for large-scale operations. This is because batch operations are performed in the background and may take some time.
Error Handling: S3 Batch Operations does not provide built-in error handling mechanisms. If an error occurs during a batch operation, you must manually identify and resolve the issue, which can be time-consuming and complex.
No retry mechanism: As of today there is no retry mechanism to process only failed objects without creating a manifest again.
To tackle this issue, we aimed to generate manifests for the failed objects using S3 Batch. However, when we initiated a job for a prefix containing millions of objects, we discovered that the job took an extended time to complete. Upon delving deeper into the S3 Batch operation and its underlying architecture, we realized that it was essentially performing a scan or a series of short List API calls on the entire 5 billion objects, incurring charges for all of the objects instead of just the millions within the prefix. Given that this process would have to be repeated for the remaining prefixes, we estimated that the overall cost has been potentially multiplied by our project cost by 2x causing an outflow of an additional 60K USD.
Here we got an interesting idea..!!!

To fix the problem of the failed objects during migrations, we took a closer look at the necessity of the data. We discovered that the objects failed due to permission issues and were likely not in use in any application flows due to their inaccessible nature. So, we worked with our team and decided either to leave the data in its original location in Mumbai or delete it
This way, we can save both time and money during the migration process!
Finally, when it comes to meeting requirements, there are numerous approaches to consider. It is critical to understand what is truly required and to choose managed services wisely. It is critical to thoroughly weigh the pros and cons, as seemingly advantageous solutions may create challenges or incur additional costs down the road. Before finalizing any solution, it’s always a good idea to do your homework and carefully evaluate options based on your needs and environment. Migrating S3 data from one region to another can be a complex and time-consuming process, but with the right approach, it can be done smoothly and efficiently.
